|
Research
My present research focuses on the development of accelerators for machine intelligence algorithms.
Previously, my research was aimed at improving the performance/energy trade-offs of Chip Multiprocessors:
organization of the multiple cache levels, complexity-effective adaptive prefetching, smarter contents placement policies, and branch prediction.
|
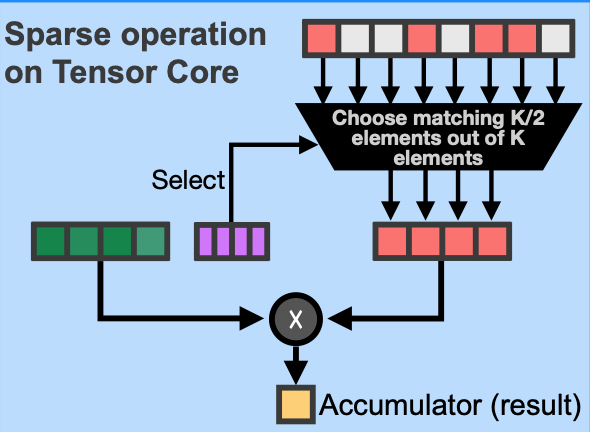 |
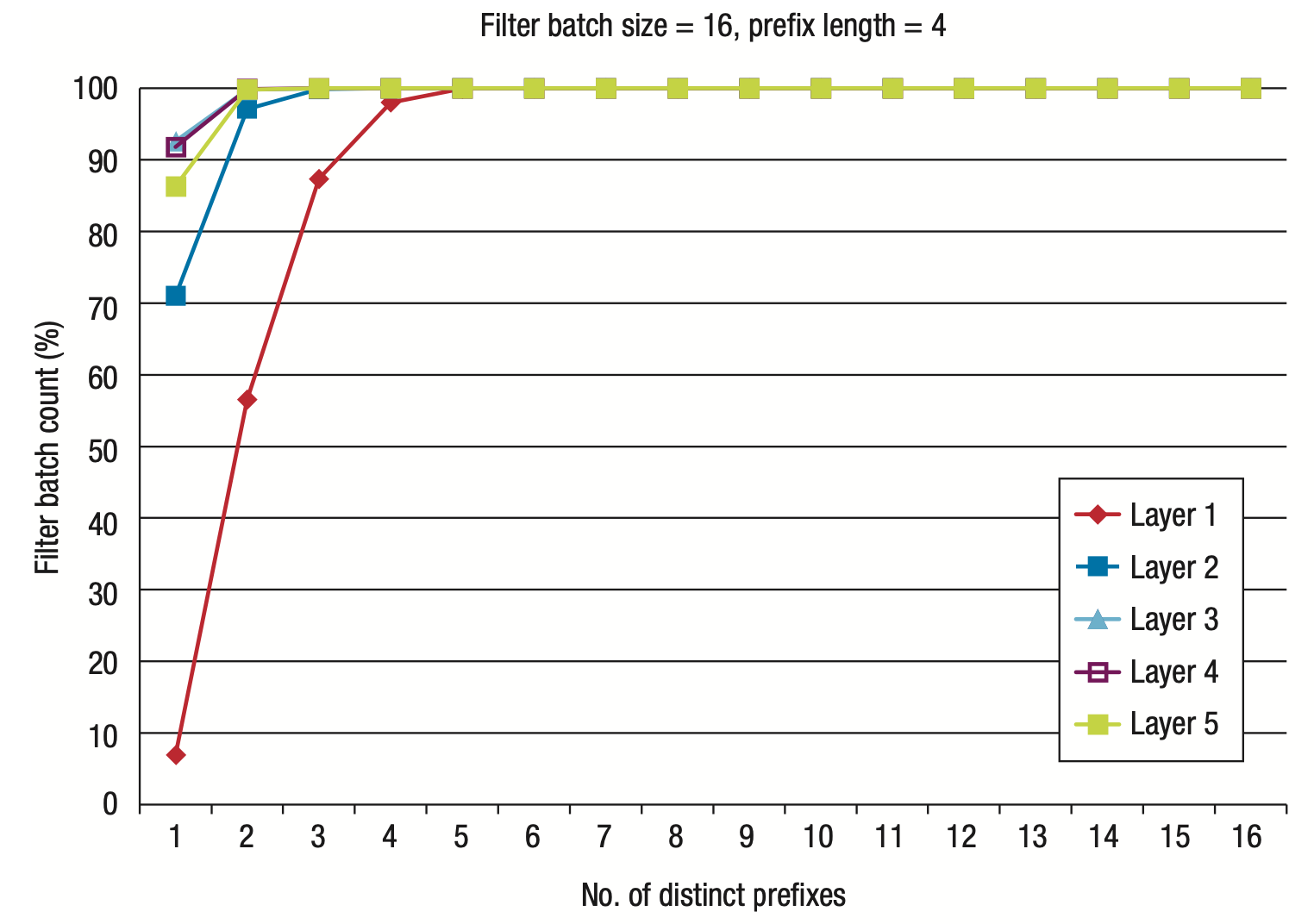
Accelerating Sparse Deep Neural Networks
A. Mishra, J. Albericio, J. Pool, D. Stosic, D. Stosic, G. Venkatesh, C. Yu, P. Micikevicius
Arxiv , 2021.
|
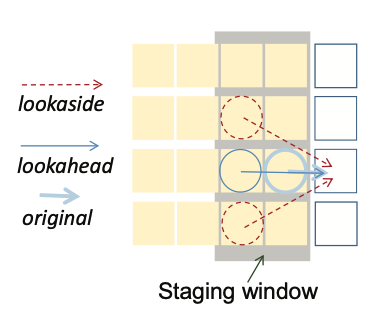 |
Tensordash: Exploiting sparsity to accelerate deep neural network training
M. Mahmoud, I. Edo, A. H. Zadeh, O. M. Awad, G. Pekhimenko, J. Albericio, A. Moshovos
In Procs. of the 53rd Annual IEEE/ACM Int. Symp. on Microarchitecture (MICRO), 2020.
|
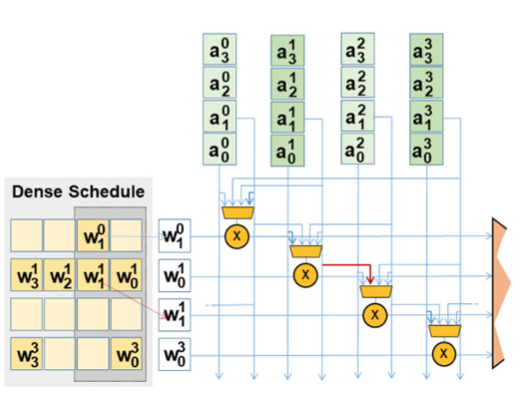 |
Accelerating Image Sensor Based Deep Learning Applications
AM. Mahmoud, D. Malone, Z. Poulos, A. Delmas, P. Judd, S. Sharify, M. Nikolic, K. Siu, I. Edo, J. Albericio, A. Moshovos
IEEE Micro 39 (5), 26-35, 2019.
|
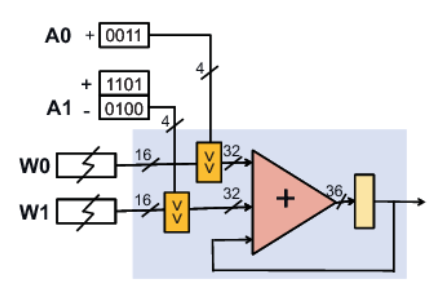 |
Identifying and Exploiting Ineffectual Computations to Enable Hardware Acceleration of Deep Learning
A. Moshovos, Jorge AlbericioJ. Albericio, P. Judd, A. Delmas, S. Sharify, M. Mahmoud, Z Poulos, T. Hetherington, T.Aamodt, N. E. Jerger
16th IEEE International New Circuits and Systems Conference (NEWCAS), 2018.
|
 |
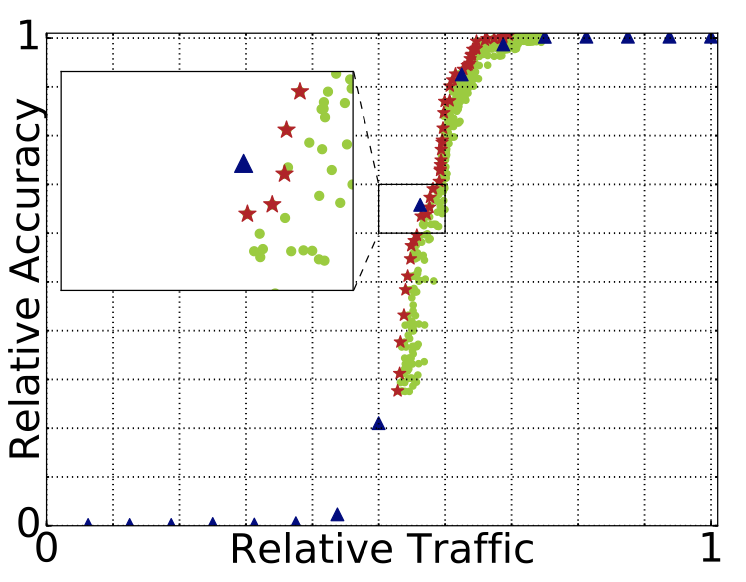
Exploiting Typical Values to Accelerate Deep Learning
A. Moshovos, Jorge Albericio, P. Judd, A. Delmas, S. Sharify, Z. Poulos, T. Hetherington, T. Aamodt, N. E. Jerger
Computer 51 (5), 18-30 , 2018.
|
 |
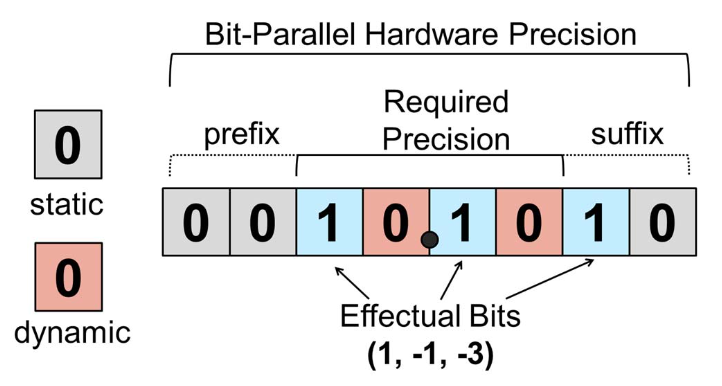
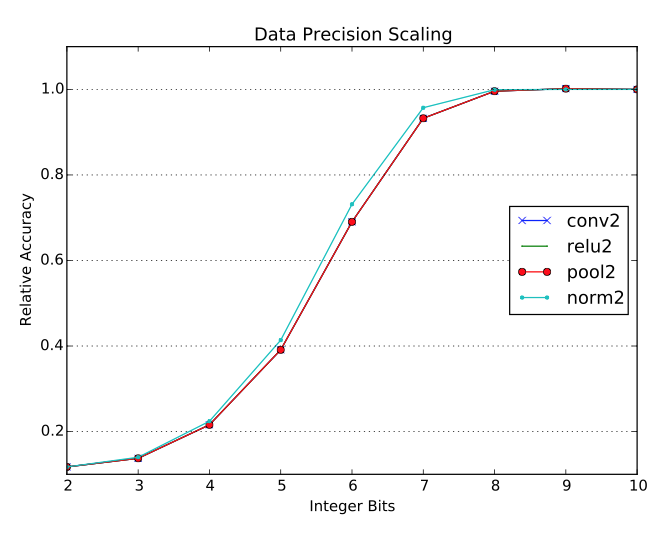
Proteus: Exploiting precision variability in deep neural networks
P. Judd, Jorge Albericio, T. Hetherington, T. Aamodt, N.E. Jerger, R. Urtasun, A. Moshovos
Parallel Computing 73, 40-51 , 2018.
|
 |
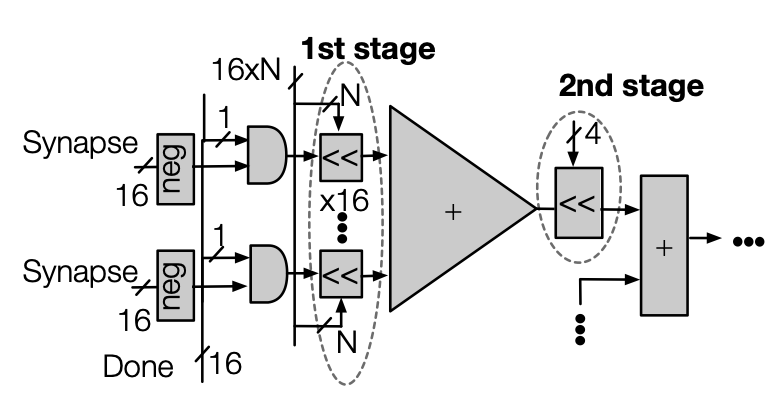
Value-Based Deep-Learning Acceleration
A. Moshovos, Jorge AlbericioJ. Albericio, P. Judd, A. Delmas, S. Sharify, T. Hetherington
IEEE Micro 38 (1), 41-55, 2018.
|
 |
Bit-pragmatic deep neural network computing
J. Albericio, A. Delmás, P. Judd, S. Sharify, G. O'Leary, R. Genov, and A. Moshovos.
In Proceedings of the 50th Annual IEEE/ACM Int. Symposium on Microarchitecture (MICRO), 2017.
|
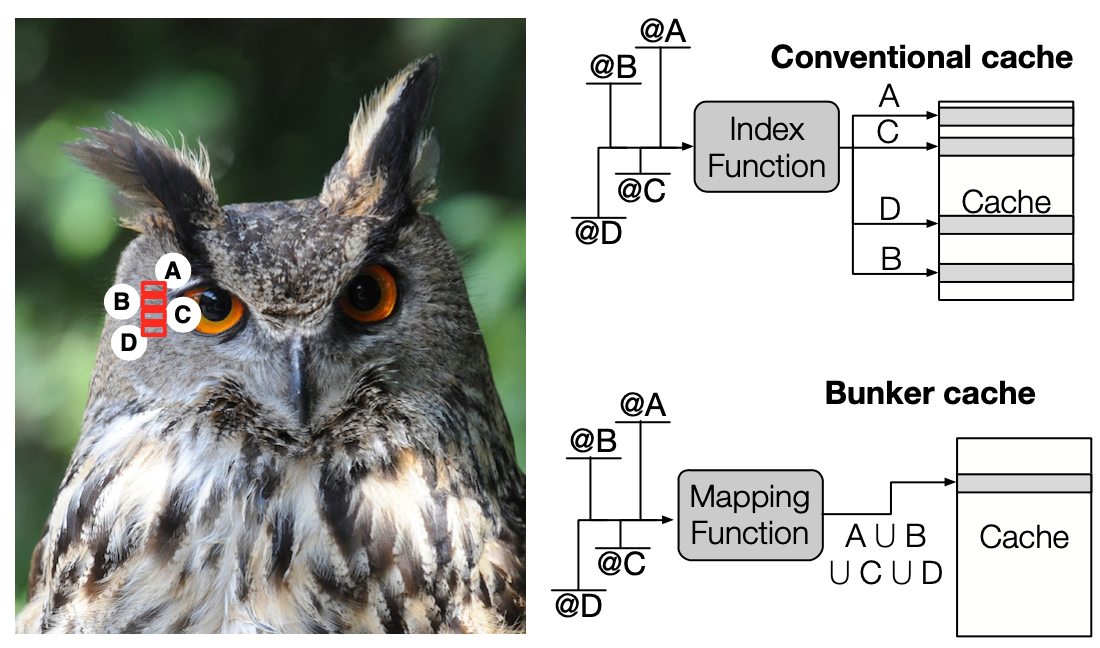 |
The bunker cache for spatio-value approximation
J. San Miguel, J. Albericio, N.E. Jerger, A. Jaleel.
In Proceedings of the 49th Annual IEEE/ACM Int. Symposium on Microarchitecture (MICRO), 2016.
|
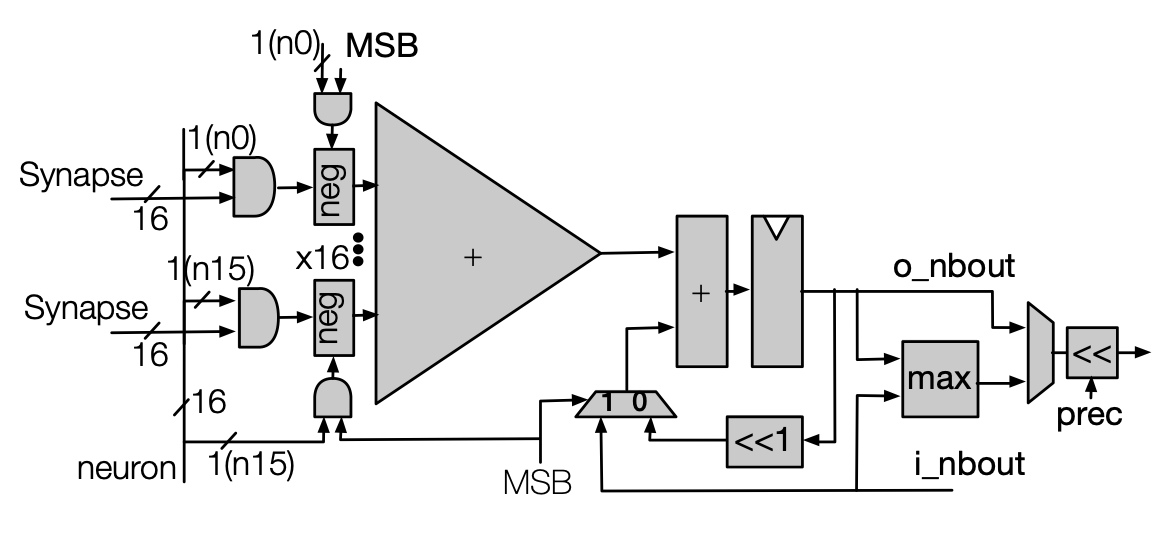 |
Stripes: Bit-serial deep neural network computing
P. Judd, J. Albericio, T. Hetherington, T. Aamodt, A. Moshovos.
In Proceedings of the 49th Annual IEEE/ACM Int. Symposium on Microarchitecture (MICRO), 2016.
|
 |
Proteus: Exploiting numerical precision variability in deep neural networks
P. Judd, J. Albericio, T. Hetherington, T. Aamodt, N.E. Jerger, A. Moshovos
In Proceedings of the 2016 International Conference on Supercomputing (ICS), 2016.
|
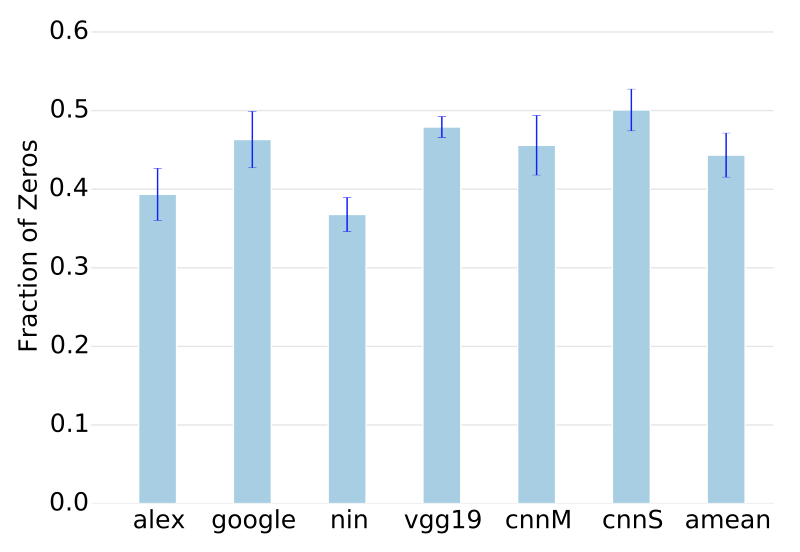 |
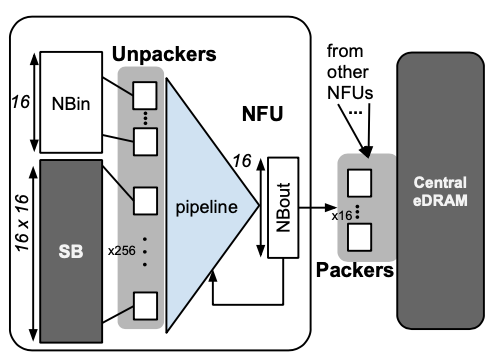
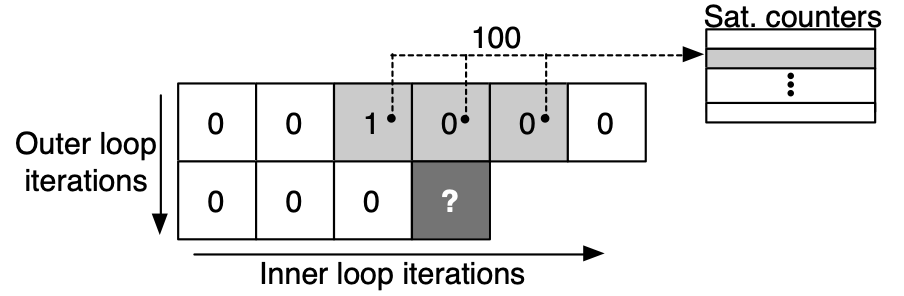
Cnvlutin: Ineffectual-Neuron-Free Deep Learning Computing
J. Albericio, P. Judd, T. Hetherington, J. San Miguel, T. Amodt, N. E. Jerger, and A. Moshovos.
In Proceedings of the 43rd International Symposium on Computer Architecture (ISCA)., 2016.
|
 |
Practical Multidimensional Branch Prediction
A. Seznec, J. San Miguel, and J. Albericio.
In IEEE Micro's Top Picks from the Computer Architecture Conferences, , 2016.
|
 |
Reduced-precision strategies for bounded memory in deep neural nets
Patrick Judd, Jorge Albericio, Tayler Hetherington, Tor Aamodt, Natalie Enright Jerger, Raquel Urtasun, Andreas Moshovos.
Arxiv , 2015.
|
 |
Doppelgänger: a Cache for Approximate Computing
J. San Miguel, J. Albericio, N. Enright Jerger, and A. Moshovos.
In Proceedings of the 48th Annual IEEE/ACM Int. Symposium on Microarchitecture (MICRO), 2015.
|
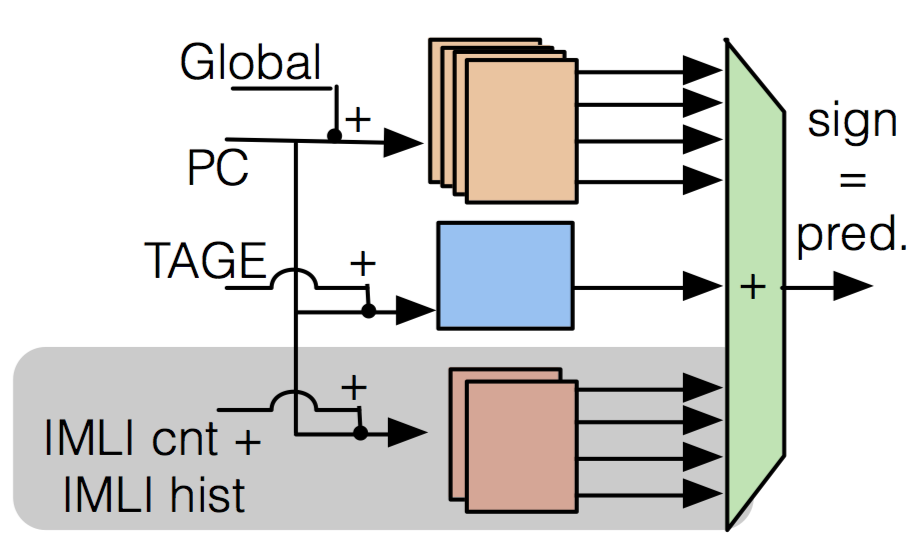 |
The Inner Most Loop Iteration counter: a new dimension in branch history
André Seznec, J. San Miguel, and J. Albericio
In Proceedings of the 48th Annual IEEE/ACM Int. Symposium on Microarchitecture (MICRO), 2015. (to appear)
|
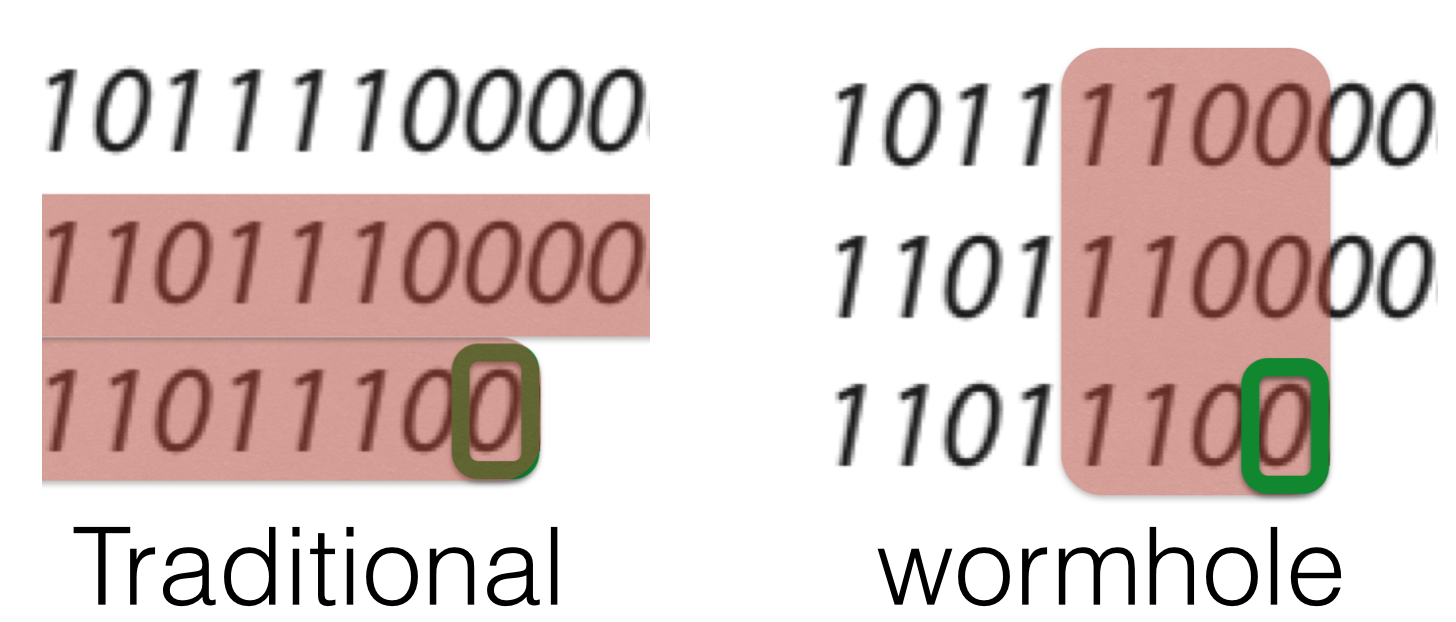 |
Wormhole: Wisely Predicting Multidimensional Mranches
J. Albericio, J. San Miguel, N. Enright Jerger, and A. Moshovos.
In Proceedings of the 47th Annual IEEE/ACM Int. Symposium on Microarchitecture (MICRO), 2014.
|
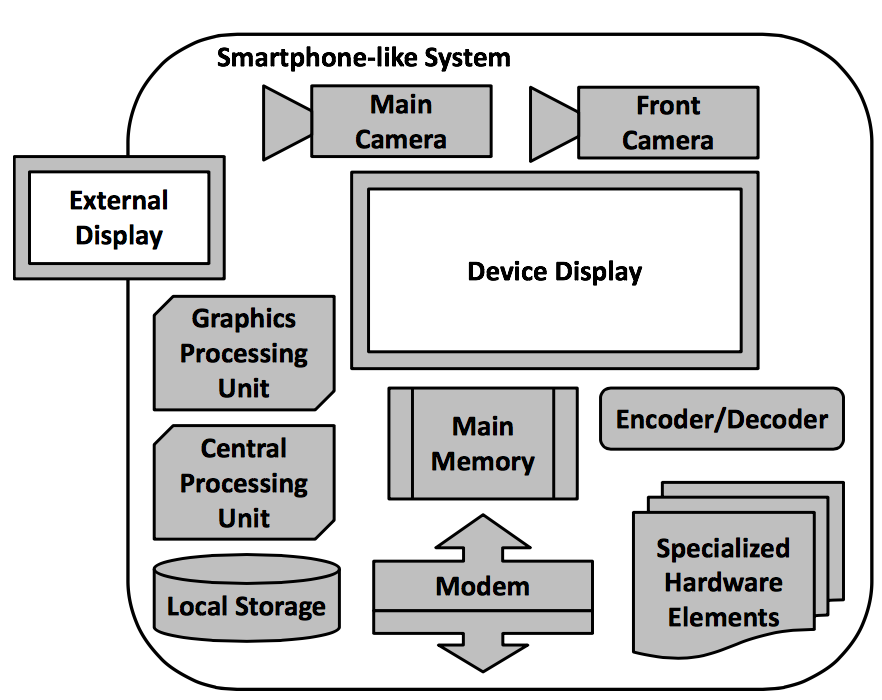 |
Evaluating the Memory System Behavior of Smartphone Workloads
G. Narancic, P. Judd, D. Wu, I. Atta, M. Elnacouzi, J. Zebchuk, J. Albericio, N. Enright Jerger, A. Moshovos, K. Kutulakos, and S. Gadelrab.
In the 14th International Conf. on Embedded Computer Systems: Architectures, Modeling and Simulation (SAMOS XIV), 2014.
|
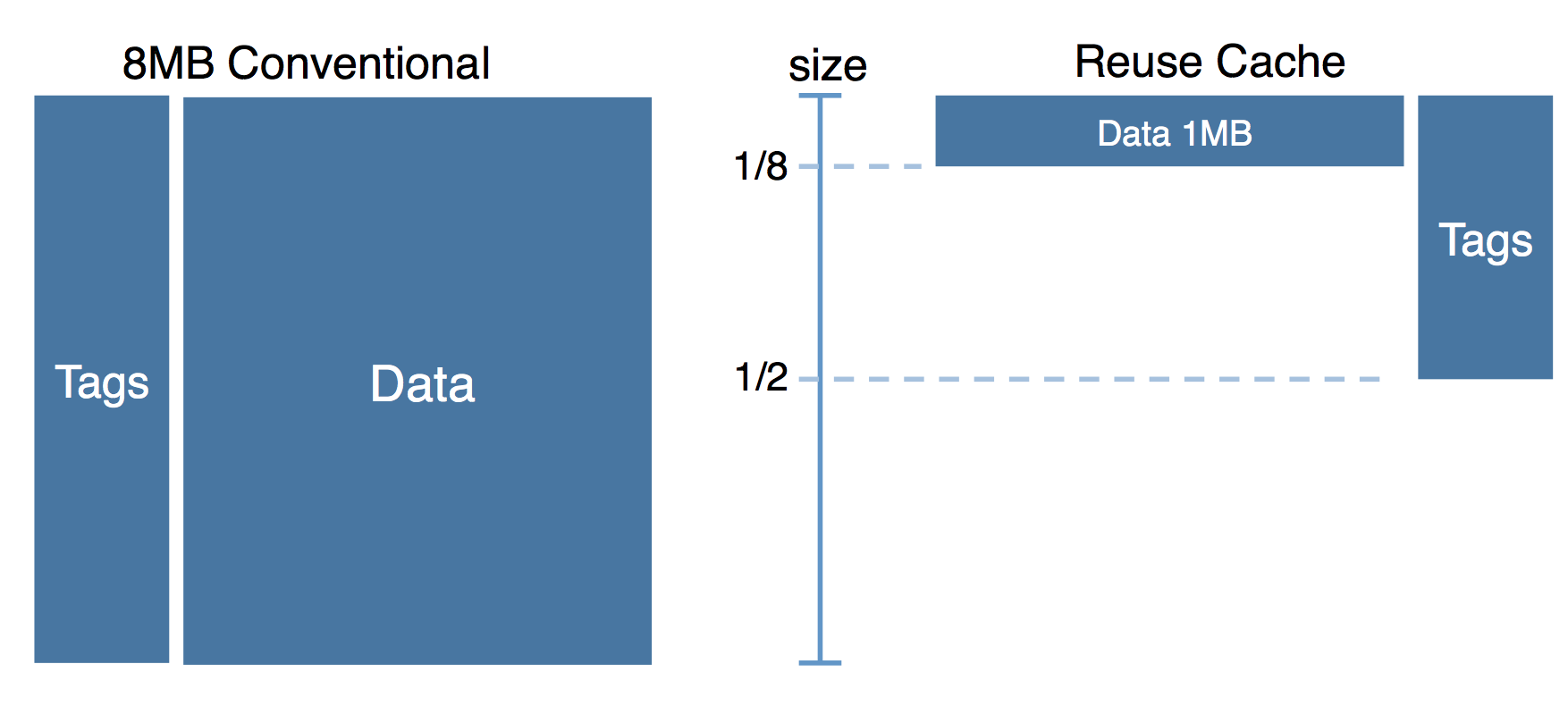 |
The Reuse Cache: Downsizing the Shared Last-Level Cache
Jorge Albericio, Pablo Ibáñez, Víctor Viñals, and José M. Llabería.
In Proceedings of the 46th Annual IEEE/ACM Int. Symposium on Microarchitecture (MICRO), 2013.
|
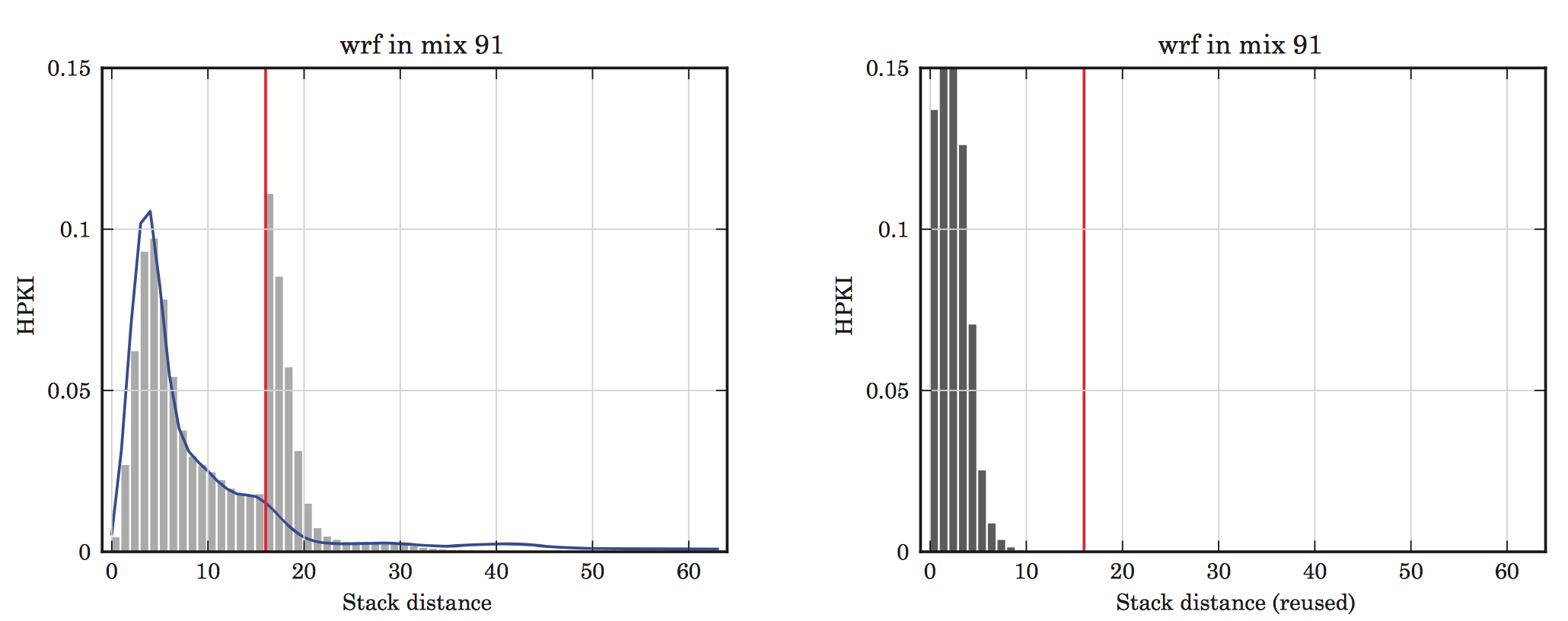 |
Exploiting reuse locality on inclusive shared last-level caches
Jorge Albericio, Pablo Ibáñez, Víctor Viñals, and José M. Llabería.
ACM Transactions on Architecture and Code Optimization (TACO), January 2013, Vol. 9-4.
|
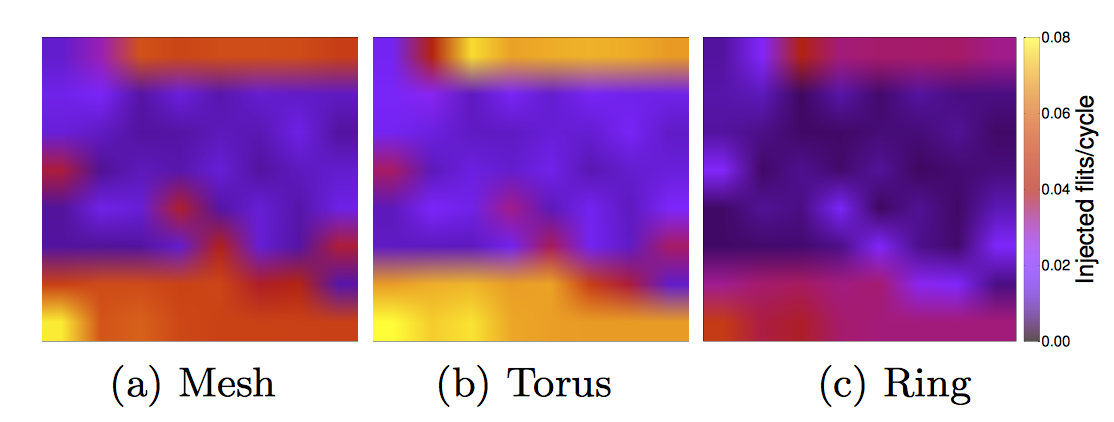 |
Characterization and Cost- Efficient Selection of NoC Topologies for CMPs
Marta Ortín, Alexandra Ferrerón, Jorge Albericio, Dario Suárez, Cruz Izu, and Víctor Vinyals
7th Int. Workshop on Interconnection Network Architectures: On-Chip, Multi-Chip (INA-OCMC), 2013.
|
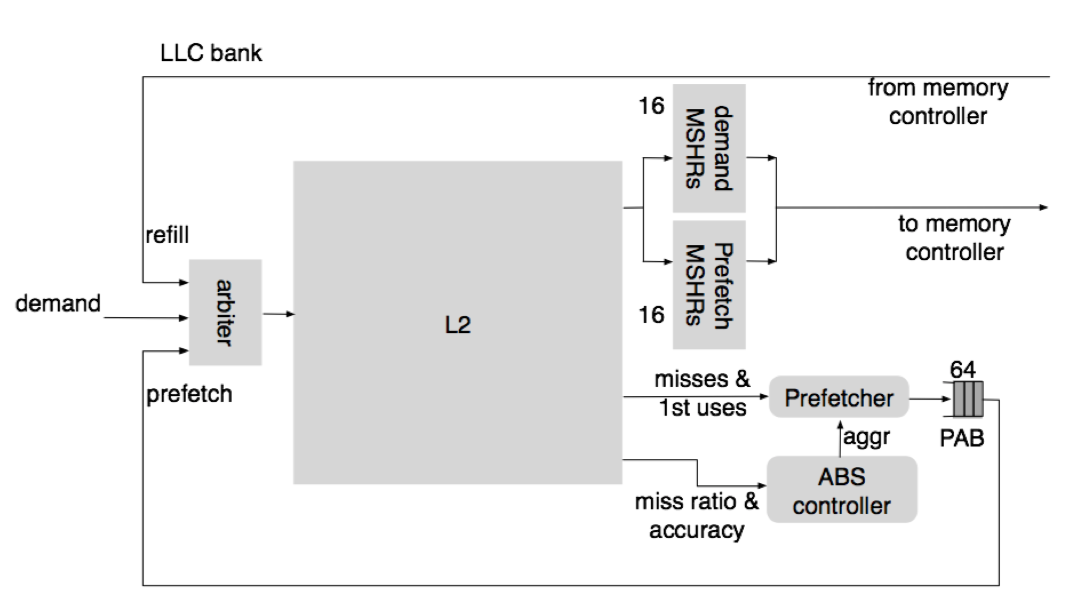 |
ABS: a Low-Cost Adaptive Controller for Prefetching in a Banked Shared Last-Level Cache
Jorge Albericio, Ruben Gran, Pablo Ibáñez, Víctor Viñals, and José M. Llabería.
ACM Transactions on Architecture and Code Optimization (TACO), January 2012. Vol. 8-4.
|
|